Research
Multi-Agent Reinforcement Learning

Many important real-world applications, such as traffic systems, networking systems, and supply chains, can be modeled as multi-agent systems, in which several autonomous agents interact in a shared environment to achieve their respective goals. Multi-agent cooperation is becoming increasingly relevant to our society as AI systems are rapidly deployed and advanced. However, enforcing such cooperation via centralized control is practically infeasible due to differences in agent goals, origins/manufacturers, observability, and a combinatorial joint-action space.
We are interested in learning decentralized policies to control agents individually to achieve cooperation in cooperative and self-interested scenarios (with or without adversarial influence). We are focusing on scalable and robust multi-agent reinforcement learning methods to learn cooperative policies in a data-driven manner.
Currently, we are pursuing the following directions:
- Scalable cooperative systems [NeurIPS-21]
- Emergent cooperation in self-interested systems [JAAMAS-24]
- Robust and adversarial training [AAMAS-20, AAAI-21]
- New training paradigms and benchmarks [ICML-23]
Multi-Agent Path Finding
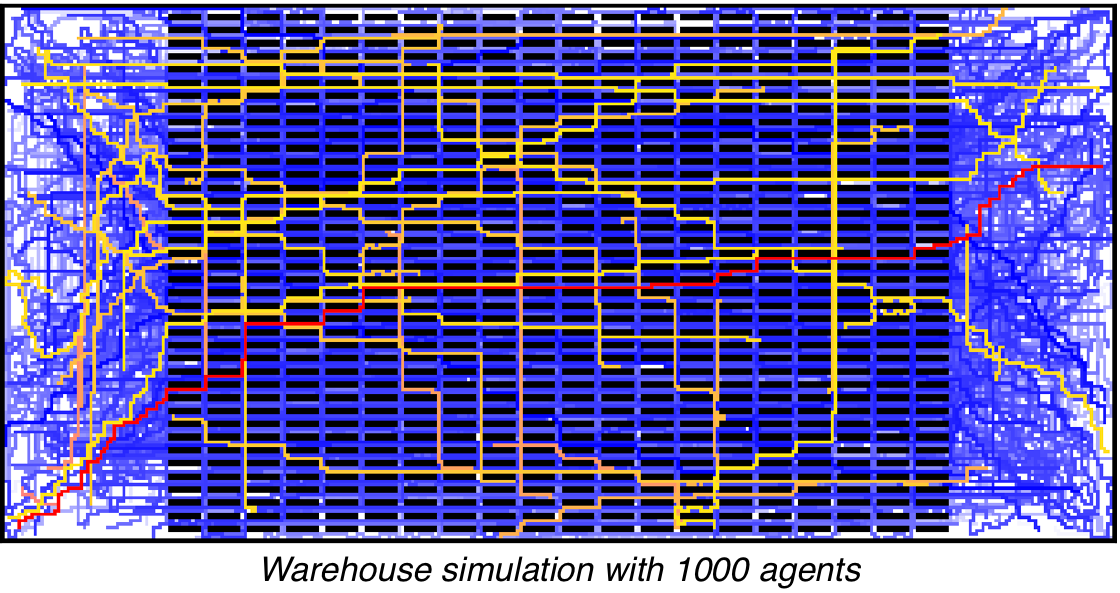
Multi-agent path finding (MAPF) is the problem of finding collision-free paths for several agents with assigned start and goal locations. Finding optimal solutions, i.e., collision-free paths with minimal costs, is NP-hard and thus intractable for large-scale systems. However, due to its relevance to real-world applications, such as multi-robot warehouses and traffic management, substantial progress has been made with suboptimal MAPF solvers that trade off effectiveness for efficiency to compute collision-free paths for thousands of agents (but with arbitrarily high path costs that could affect fuel consumption and wait times).
We are interested in developing adaptive MAPF solvers to improve the effectiveness of current suboptimal solvers while maintaining their original efficiency. Therefore, we employ reinforcement learning methods, ranging from multi-armed bandits to spatio-temporal curriculum learning schemes for decentralized path finding.
Currently, we are pursuing the following directions:
Hybrid Decision-Making in Multi-Agent Optimization
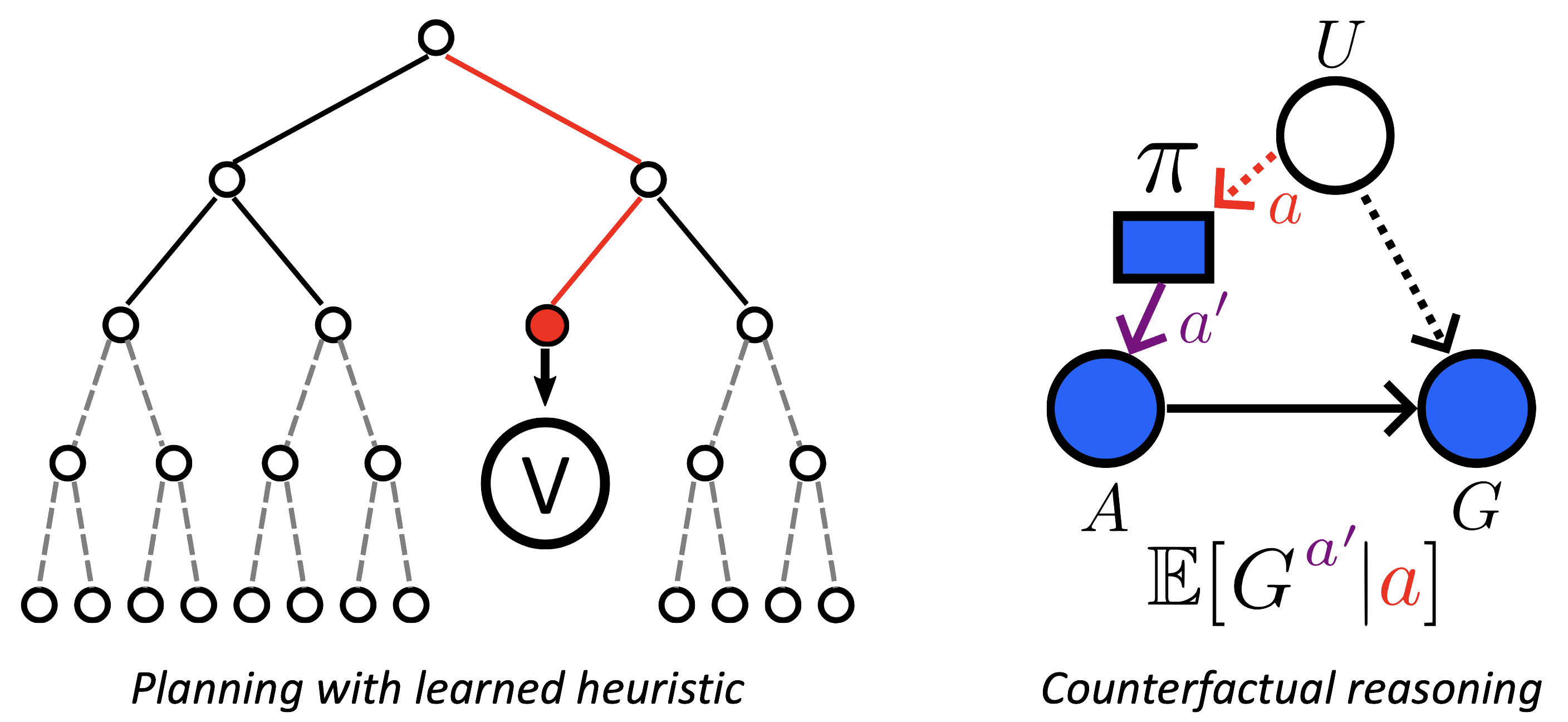
Many AI systems rely on planning and learning techniques to make strategic decisions. Strategic decentralized decision-making in complex multi-agent scenarios is challenging due to non-stationarity caused by simultaneous agent planning and/or learning, and unawareness of other agents' objectives. Therefore, centralized methods for decentralized control have become popular, leveraging global information to enforce coordination during planning and learning to produce decentralized policies that can be executed independently under partial observability.
However, centralized planning and learning only work in idealized scenarios, where all agents are known a priori and where the global information matches the partial information perceived by the decentralized policies sufficiently. To address these issues, we are investigating ways to combine planning and learning effectively to enable principled reasoning and adaptation in a cooperative manner.
Currently, we are pursuing the following directions: